Process monitoring equipment needs – as told by a valve in a mineral processing plant.
by Mariana Sandin
Hello. I’m just a valve – one of thousands, maybe hundreds of thousands – in a global mining operation, part of the utilities group in my facility. I don’t ask for much: a little grease, the occasional calibration, and the hope that someone tends to my bearings before they leak, stick, or fail altogether.
Lately, however, I am noticing more attentive watchfulness. Sensors track my every move, and my flow rates, temperatures, and oscillations are logged in real-time. There are increased murmurs of “operational and enterprise monitoring,” which sounds sophisticated, but here’s the thing: I’m still not sure anyone really sees me. Not me, not my symptoms, not my signals.
And I’m not alone. My fellow valves, pumps, filters, and conveyors across the operation – we’re all blinking our little alarms, hoping someone notices. Hoping someone cares.
So let me tell you what we need, and spoiler: it isn’t just monitoring. We need understanding, context, coordination and action. And yes, some artificial intelligence (AI) support would be nice to accelerate the creation, replication, and sharing of knowledge about the right conditions to monitor.
What does “monitoring” really mean?
“Monitoring” is noticing when something small has the potential to become widespread and far-reaching. But in the chaos of a processing plant, where everything is always changing, it is easy to miss early signs. This concern further intensifies when human operators are expected to stare at grayscale human-machine interfaces (HMIs) all day.
Operators are typically presented with screens full of data points that remain within normal ranges most of the time, but abnormal does not always scream. Oftentimes, it whispers over a long period, with small performance drifts and subtle correlations compounding over time. These understated underpinnings are easy to miss.
One of my fellow plant equipment colleagues, a refinery pump, was outfitted with new vibration sensors. The new data these sensors generated was collected within historical databases and added to univariate models, and this procedure was later scaled out to a group of 4,000 pump friends. With over 38,000 variables analyzed among the group, the plant needed to implement an alert management system to efficiently triage the severity of various conditions to effectively monitor the assets and prioritize human effort.
To accomplish this, the refinery partnered with their technology partner, Seeq, to implement a robust yet flexible solution, easily scalable to other asset groups, such as valves like myself. When all was done, the group increased mean time between failures (MTBF) by 10%, enhancing the useful life of all associated production assets.
Monitoring, in this context, is not about watching, but about noticing meaningful change – the kind of changes that indicate when a process downstream may go awry. For example, when someone notices I am leaking, is that an unexpected issue, or is it part of standard wear and tear? Is my oscillation pattern a one-off, or a sign of impending failure? The answers to these questions inform logical next steps to keep production on track.
This is where AI, predictive analytics, and digital workflows are handier than ever before – not to replace humans, but to augment their vision and show them what we valves can’t tell them outright. (I am a special case, able to communicate with you humans through an interpreter.)
One process manufacturer in the UK was experiencing issues maintaining a sufficiently-staffed talent pool to sustain the number of process engineers tending to operations, let alone sharing knowledge with new hires. This facility had recently introduced predictive analytics digital workflows in an effort to automate familiar and repeating tasks. Some resulting recommended actions needed to be reviewed prior to execution, while others occurred automatically. However, this implementation did not solve the problem of capturing, transferring, and enhancing knowledge.
To meet this need, the facility integrated generative AI (GenAI) – which learns from existing data – into its workflows with the audacious goal of capturing 100 years of corporate experience in the period of a few months, then using this information to train employees. Leadership saw good results, giving them the confidence to cut the required time for a brand-new process engineer to promote to process expert in half, helping solve the company’s talent pool concerns.

The scaling problem
Imagine you are responsible for monitoring 100 valves. One day, your boss puts you in charge of 3,000 times the amount you’ve grown accustomed to. How do you decide which of the 300,000 valves to look at first?
Prioritization quickly becomes crucial in this context. Not all alerts are equal, and not all exceptions are true exceptions. Furthermore, different assets operate under differing environmental and operating conditions.
AI and advanced analytics can help filter the noise and display the information that matters most. However, these tools need consistent and accurate data to work reliably. In the not-so-distant past, this data also needed to be cleansed, standardized and contextualized, but leading modern AI tools are natively capable of making sense of the chaos to compare apples-to-apples, valve-to-valve, asset-to-asset.
When something does go wrong, how do you respond? How do you notify the right person, or the right system, in time to prevent a shutdown? Some actions can be automated, while others must wait until a scheduled stoppage, but in all cases, flexible workflow execution is key. For example, when I identify an issue, I share the load with a secondary valve and pipeline until the next shutdown or other maintenance window. However, if any of the assets on the secondary line are out for repairs, redundancy is gone. This is why tagging, communicating, annotating, and acting quickly when issues are identified is critical.
Monitoring is not just looking – it is creating
Monitoring is a two-way street. It requires observation, but it also means creating context. When I leak, someone needs to know why. Maybe it was caused by a pressure spike, maybe it was due to faulty maintenance on the wrong gasket, or perhaps it was just my time. But unless someone logs this context – through annotations, root cause comments, or automated detection – the insight is lost, and the event is destined to repeat.
The best systems make it easy to add and retain human insight. They do not force engineers to select “other” from a drop-down list or hide tracking tools under numerous layers of complicated computer code. We can do much better. Annotations should be simple and flexible, while retaining the ability to record maximum context.
Each small annotation creates untold value for other teams across a plant, site, or even the entire enterprise. They can also be leveraged by the intern starting next summer, who may be a supervisor in a few years.
From alarm fatigue to intelligent action
We valves know operators are drowning in alarms. Alarm fatigue is real, trust me, we see their faces. Some systems generate hundreds, even thousands, of alerts daily. This is way too much noise, and nobody strives for it. The result? Alarm disablement. Just turn off notifications. Not ideal.
The goal should never be more alerts. Instead, it should be intelligent and better alerts, and ideally, fewer of them. How does a plant reduce thousands of daily notifications to only a few that matter? Getting there requires smarter logic, better analytics, and adaptive workflows that can adjust based on operational priorities, risk, personnel availability and open maintenance windows.
Not everything can or should be automated, but everything should be centrally connected to fuel condition-based monitoring (CBM), predictive analytics, and machine learning to provide an hour, a day, a week, or even a few weeks advance notice of conditions starting down the slope to failure.
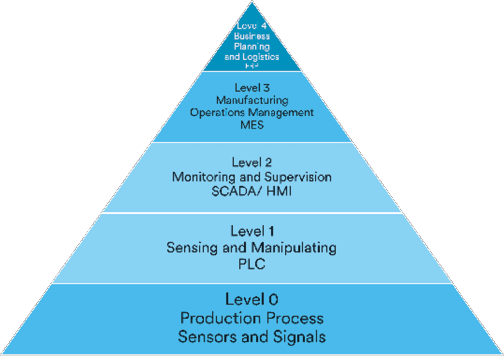
Beyond the plant – the rise of enterprise monitoring
Traditionally, monitoring systems were localized in plants, close to the equipment. Think control systems and historians occupying Levels 0 through 3 – and sometimes 4 – in the ISA-95 model (see Figure 2): on-premises, rugged, and essential.
However, mining operations today are global and integrated. Level 4 – the business systems layer – is moving to the cloud, and enterprise monitoring means scaling local insight accordingly from mine to port, asset to control room, site to headquarters, and on-prem to cloud.
Platforms like Seeq are enabling this shift securely, empowering subject matter experts to analyze time-series data, overlay it with contextual data, and create reusable dashboards and workflows. Additionally, AI assistants now in the mix are facilitating faster onboarding so even junior engineers can solve critical problems in days or weeks rather than years.
GenAI is also helping scale human expertise by accelerating learning and amplifying the value of monitoring systems already in place. We valves greatly appreciate this because when the right person gets the right signal at the right time, maybe – just maybe – we won’t get the blame for a breakdown that could have been prevented.
A plea from the field
Whether you are reading this from a control room, corporate office, remote operating center, or on the move – thank you. We know you’re trying.
Just remember, we valves may be small, but we are many. And we count on your expertise and software-augmented decision-making to ensure that monitoring entails more than just watching. It means understanding, acting, and optimizing operations so we can do our job and regulate the flow.
About the author: Mariana Sandin leads the mining, metals, and materials practice at Seeq, with 20 years of experience in enterprise industrial software and analytics. She has an MBA and a BS in Chemical Engineering.